The goal of a consensus algorithm is to allow multiple machines to work as a
coherent group which can survive the failures from some of its members.
Paxos has been the most common consensus algorithm used around, yet it is quite
hard to understand, and hard to implement.
In this paper, the authors introduce Raft, a new consensus algorithm meant to be understandable, as opposed to Paxos.
Replicated State Machines
Consensus algorithms are typically used when setting up replicated state
machines.
Several machines will connect with each other to share a common state and
replicate it. If one or some machines have a failure, the rest of them will
continue operating normally, therefore increasing reliability.
Replicated state machines typically use a replicated log. Each server keeps a
log of commands that need to be executed in order.
The consensus algorithm’s role is to keep that log consistent across all
machines.
They ensure the following properties:
- Safety - they never return an incorrect result, no matter the (non-byzantine) conditions.
- Functionality - they are fully functional as long as any majority of the servers are operational.
- Timing - they don’t depend on timing to ensure consistency. Clock skew doesn’t cause failure.
- Speed - As soon as the fastest half of all servers has responded, the command can complete. Slow servers don’t slow down the cluster.
Understandability
Understandability is achieved by having a constant focus on it. Whenever, when
building the protocol’s design, two alternatives were possible, they always
focused on the most understandable one.
While this is very objective, they used two techniques to make those decisions.
- Problem Decomposition: Wherever possible, they divided problems into separate pieces that could be solved, explained and understood independently.
- Reduce the number of states: this allowed making the system more coherent and reduced non-determinism.
Raft
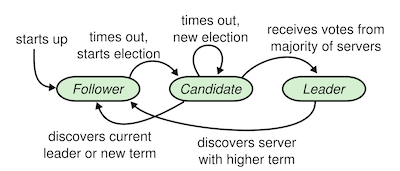
Any Raft cluster has a single leader, and many followers. Ideally, there should be at least 5 servers, so the cluster can tolerate two failures.
New nodes will start with the follower state, listening for log updates from the leader.
Leader Election
If a node doesn’t receive any updates from the leader, they time out, considering there no available one. A new election ensues.
When performing an election, the first node to time out starts a new election,
transitions to the candidate state. It then requests votes from each other node
in the cluster.
When receiving a vote request, nodes are expected to approve or reject the
vote. They can only approve one node as being the leader per election round.
When a majority of nodes have approved the election, the node is appointed
leader and can start streaming logs.
Log Replication
Once a leader has been elected, it can begin servicing new log entries and replicating them to other nodes.
Any new log entry goes into an uncommitted log. The leader then transmits it to
each node, and wants for their replies.
Once half of the nodes have approved the new log, the log can be approved, and
be moved to the committed log.
The request to add new log entries can fail until the event is moved to committed. That allows rejecting new lines if they won’t be committed, while not having to wait for the slowest node to acknowledge the change.
Safety
Raft provides several ways to ensure safety of the logs data across leaders election.
A term is shared across nodes, which is incremented whenever a node creates a new election. Log entries appended, or new elections with the wrong term will be rejected.
Section 5.4 shows how the leader election completeness allows for safety of the stored data.
Snapshots
Over time, the raft log will grow, and it will take more and more time to start
new nodes, as they will have many log lines to apply before being available.
For this reason, raft allows applying snapshots.
A snapshot includes 3 information:
- The last included index
- The last included term
- The expected state of the state machine
With the last included index and term, the node can accept any new log entry
that is being transmitted.
With the expected state of the state machine, all previous log lines, allowing
to build the FSM into its final state can be discarded.
The leader decides when to send a snapshot request, if a new node is
connecting, or one is lagging too far behind.
When receiving a snapshot, the node is expected to discard its log, to set the
state machine to the provided state and to accept new requests coming later.
Conclusion
This a very interesting paper, and the understandable is definitely not
an overstatement.
While the need for implementing a consensus algorithm should be pretty rare
(build stateless services instead), doing so with raft would definitely make
sense.
And while I’m sure it wouldn’t be trivial, it doesn’t seem like it would be
such a big problem to implement though.