One of the books that impacted the most my career is probably The Mikado Method. I read it almost 10 years ago, and I don’t practice it explicitly. But I think of the method almost every day, and it has been impacting how I work ever since.
And yet, it has remained something quite obscure. Whenever folks suggest must-read computer science books, it’s never there. So let’s try to explain it a bit more, and how it can be used every day in the life of a programmer.

What is the Mikado Method?
If you ever worked on a large refactoring project, library switch or upgrade,
you may have ended up working in a branch for weeks (or months).
You need to regularly rebase against the main branch (or have everybody working
on the same branch), and may end up spending more time fixing conflicts than
actually working on the change.
But somehow you move forward, and one day you are ready to ship that huge change.
The biggest bet still lays ahead of you though: will there be performance
changes? Did we miss something? Were there unknown bugs?
In my experience, every big bang change always ends up in at least one cycle of
reverting and going back to the PR, and a non-trivial number of them were not
shipped at all.
The Mikado Method is a framework to make that kind of refactoring manageable.
The idea is to split things into atomic changes. Each of these changes will be shipped right away, on its own.
Let’s say you’re working on a Ruby on Rails application which hasn’t been upgraded in several years. So you need to go from Rails 4 to Rails 7 (wow!).

Let’s do it with some mikado!
The first step will be to locally upgrade the rails dependency in your
Gemfile to the final version you want to run on.
On a paper, draw a rectangle (or a circle, anything) and write down a couple
words about the task you’ve just down, such as upgrade rails in Gemfile.
Now, run your unit test suite. Obviously, there will be lots of failures.
Go through each failure, and for each of them write a new rectangle on the
paper, with a (very) short description of what you would have to do to fix that
issue. If the cause is unknown at that point, you can also write down the
failure itself, to be investigated.
Link each rectangle to the parent one, as can be seen in the example image
below.
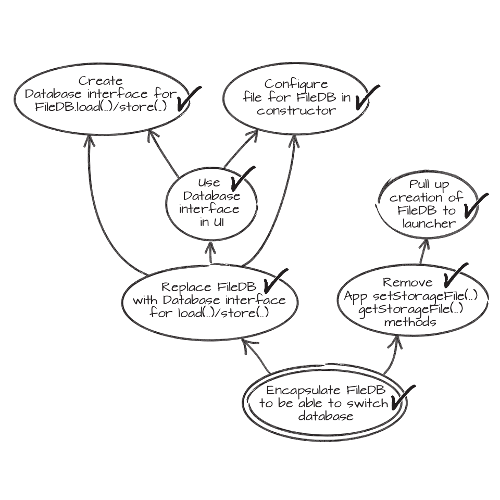
Then, revert your changes. Delete everything!
And I really mean revert, not move to a new branch or squash.
If you feel this change took you too long to just be deleted, it means it
wasn’t atomic enough and you need to split it.

Now, pick one of the failures you wrote down, any of them and try to fix it in
the current codebase, without the original upgrade.
Doing so may require some refactoring or more changes. In that case, don’t do
them. Write them on your paper, delete everything and start implementing
them.
Similarly, if after fixing the problem, there are still failures, write them
down, link them to the issue you were just trying to fix and delete everything.
And iterate from there against every failure, refactoring or change you need. If you discover a new issue, write it down and delete everything.
At some point, you will get a fix which actually works and for which all your tests pass. Ship that change!

And move on to the next failure.
Over time, you will get more and more actual fixes, and less and less reverts. Until all there is left to do is to make the change where you actually change the content of your Gemfile to upgrade the dependency version.
At that point, your application supports both versions, making that change very small and trivial to ship. Do it of course!
Obviously, the Mikado Method cannot work if you don’t have a good and highly reliable automated test suite.
Wow dude, this is too much
It absolutely is. And I haven’t heard of anyone following this process to the letter.
But processes aren’t meant to be followed to the letter. They are meant to provide a frame. Once that process is fully understood, getting out of it can be beneficial, to adapt it to your own needs, while retaining the core ideas and goals of that process.
In the case of the Mikado method, I think the biggest takeaways are to ship atomic changes, and not be afraid to drop things if they derail.
Atomic Everything
There’s nothing worst (well …) than seeing a Pull Request describing something, but where other unrelated (yet relevant) changes crept in.
Whenever I am working on something, and I notice something else in the same bit
of the codebase which should be changed or refactored, I take a note of it, and
come back to it once my original change is ready for review.
I see this as a lighter way of doing Mikado. And yet, everything in a PR is
related to the same thing, making its review much easier.
One way to cheat about this would be to name the PR “do this and that”. Well,
don’t!
If your PR includes an and, there should be two of them (the same goes for
issues).
The gist of it is: split everything you do into the smallest bit possible, and ship all those bits independently.
A failure of an example
Here is an example why thinking about everything atomically is safer. At $PREVIOUS_EMPLOYER, we wanted to migrate from Opentracing to OpenTelemetry.
Both libraries are quite similar, but we had some heavy internal things that
couldn’t work exactly the same between both of them, so we wanted to ensure
there were no performance regression with the change.
Hence we decided to do a big bang PR to be able to run performance tests.
I worked for over a month just making the appropriate changes, the PR was huge,
and then I worked for another month just on the benchmarks.
Until we were ready to ship the change.
Due to errors unseen before and uncaught by unit tests, Wwe shipped and reverted 3 times before deciding to drop a quarter of work and restart from scratch with small PRs we could ship daily.
To be fair, this quarter wasn’t entirely lost, since it brought us benchmarks we wouldn’t have had this soon were it not for a big bang change. But the frustration was there anyway. And I am sure that if we had decided to keep on trying to ship that big bang PR, we would have ended up reverting more than 10 times.
Delete your WIP code
I am sometimes stuck into a fix that seems daunting. The more I fix things, the
more there are to fix, and it seems like I’m never going to get over it.
Well, this is exactly the kind of moment where deleting everything and starting
from scratch again is highly beneficial.
Once again, I do mean delete. Not squash or branch off of. There is a real psychological value in deleting a change where you’re stuck to start fresh.
However, when you do that, you should start working on the new fix right away.
Don’t wait for a couple days.
You don’t have the code available, but your mind is still there. That’s what’s
going to allow you to go back there much more quicker and better than you did
the first time.

Said like this, it may seem the need to delete WIP code like this is pretty
exceptional. I’ve personally grown to make it quite standard.
Whenever I spend more than 15-20 minutes stuck on something, I’m usually going
to delete it and start fresh.
This can only work because I am a bit extreme about making everything atomic.
So I also very often have something that works and I can commit.
When that happens, I only delete whatever’s not been committed yet. Not all the
unpushed commits I made earlier. Every of those atomic commits must have a
green local test run of course.
Conclusion
Mikado is much like the agile method. It’s something everybody should apply to
some degree, but not follow to the letter.
But working with it in mind provides a very good base to ship code (whether it
be a small bugfix, or a very large refactoring) in a safe and reliable way.
It’s probably not something everybody should do as described in the book (though if you do try it for a large enough project, I’d be happy to hear about it). But I am convinced that having some experience of it will make anyone a better developer!